Masterarbeit
Wissensbasiertes Multi-Agenten-System zur Bildklassifizierung

Details
Europa kann auf deutlich weniger Daten zurückgreifen als die USA und China (vgl. Castro et al. 2021). Dies könnte die Entwicklung künstlicher Intelligenz in Europa nachhaltig negativ beeinflussen, da Machine Learning in der Regel große Datenmengen benötigt. Aus diesem Grund soll im Rahmen dieser Arbeit ein wissensbasiertes Multi-Agenten-System zur Bildklassifizierung erkundet werden.
Dazu wird in drei Schritten vorgegangen: Theorie, Analyse und Synthese. In diesen Teilen wird stets ein Bottom-Up-Ansatz verfolgt. Zuerst wird die Feature Extraction und die Wissensbasis beleuchtet, dann die Agenten und abschließend das gesamte Zusammenspiel in dem Multi-Agenten-System.
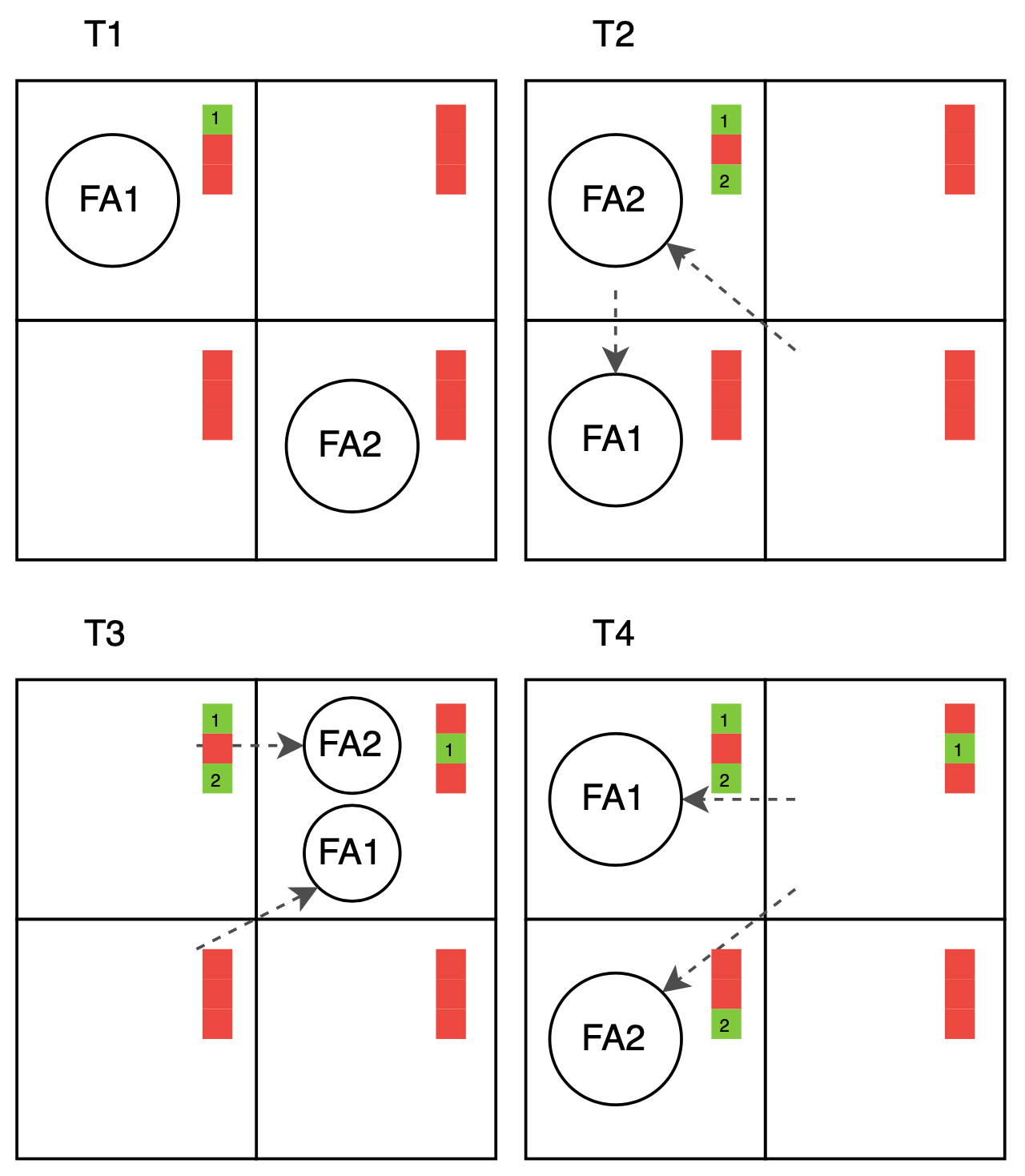
In dem entwickelten System existieren u. a. reaktive Agenten, die Umwelt – ein Gitter – dieser und eine Wissensbasis als zentrale Bestandteile. Die Wissensbasis wird direkt in die Blackboards des Gitters übersetzt, mit denen die Agenten kommunizieren und sich ihr Meinungsbild bilden. Jeder Agent erhält genau ein extrahiertes Bildfeature. Die Ausgabe des Systems erfolgt durch ein Abstimmungsverfahren (oder eine Auktion) und ist detailliert, wodurch sie von Menschen nachvollzogen und verstanden werden kann. Außerdem kann – basierend auf der Ausgabe – hergeleitet werden, welches Feature die Agenten bekommen haben, was eine gewisse Transparenz auf die internen Abläufe darstellt.
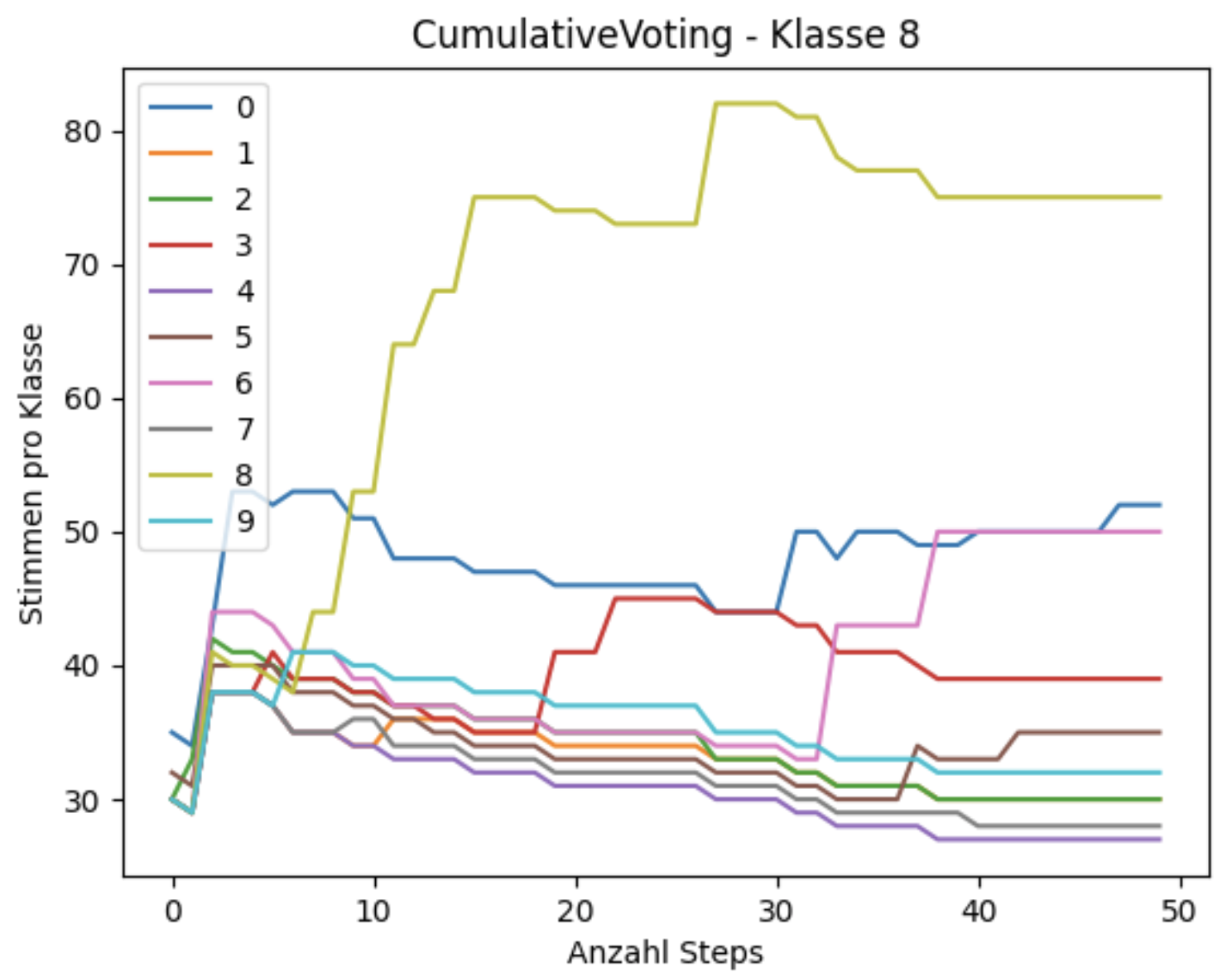
In der Evaluation wird festgestellt, dass ca. 20 Agenten mit ca. 100 durchgeführten Schritten und Cumulative Voting als Methode zur globalen Entscheidungsfindung am besten geeignet sind für den vorliegenden Anwendungsfall. Insgesamt wird das System auf drei Datensätze angewendet. Zunächst wird ein synthetischer Datensatz, welcher die Ziffern „0“ bis „9“ verschiedener Schriftarten enthält, verwendet. Dieser dient dazu, eine erste Überprüfung und Konfiguration des Systems zu ermöglichen. Anschließend wird die Robustheit gegen Rauschen auf einer verrauschten Variante des synthetischen Datensatzes durchgeführt.
Abschließend wird der Versuch unternommen, das System auf den MNIST-Datensatz für handgeschriebene Ziffern zu übertragen, was eine Herausforderung darstellt. Allerdings kann gezeigt werden, dass die Hinzunahme eines weiteren Features die Genauigkeit auf den MNIST-Daten anheben kann. Aus diesem Grund (und der Ergebnisse auf den synthetischen Daten) konnte die grundlegende Machbarkeit eines wissensbasierten Multi-Agenten-Systems zu Bildklassifizierung nachgewiesen werden. Allerdings ist das System im aktuellen Stadium nicht konkurrenzfähig gegenüber etablierten Technologien (wie z.B. CNNs).
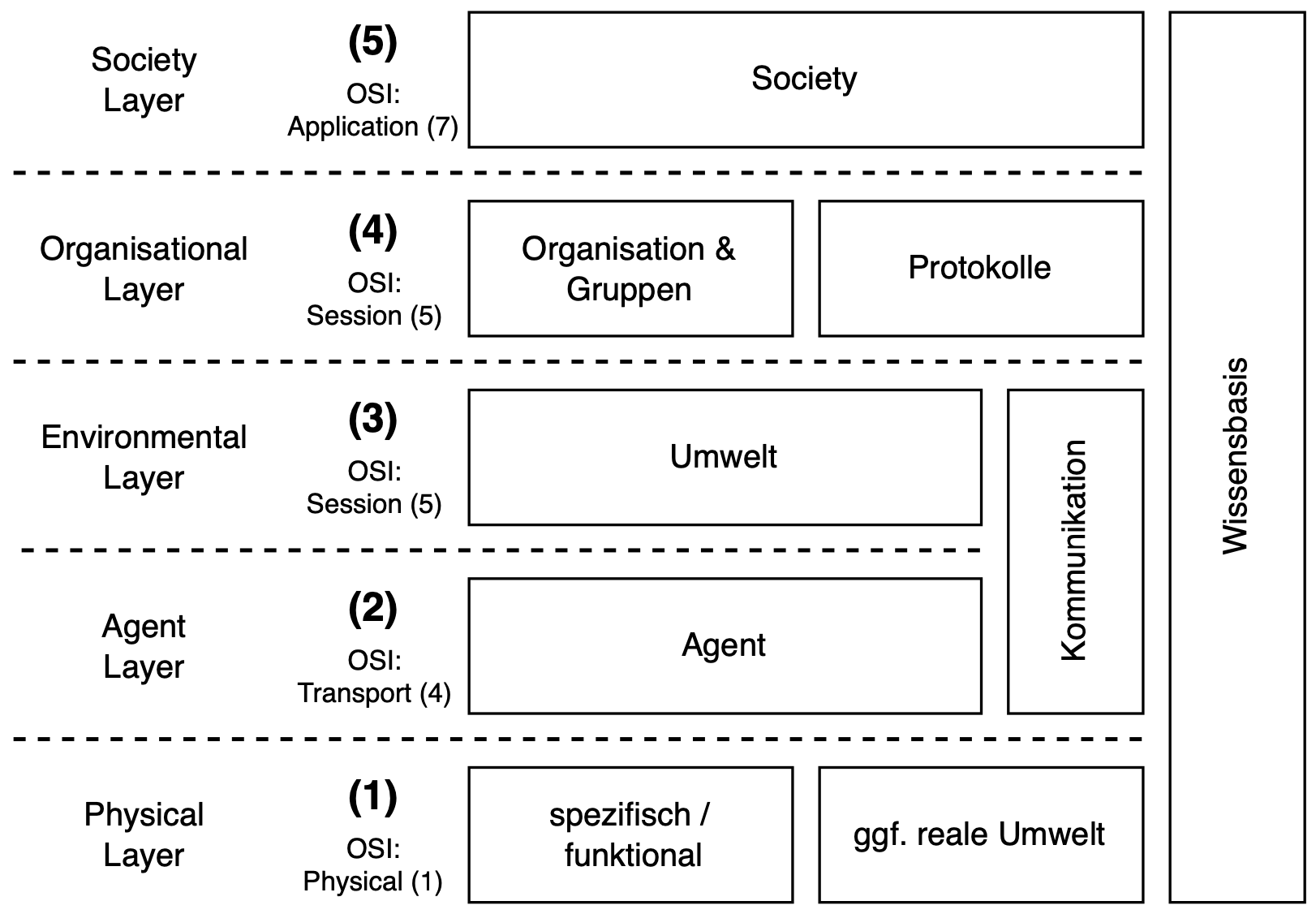
Zusätzlich wird ein Schichtenmodell zur Beschreibung von Multi-Agenten-Systemen entwickelt, welches der Komplexität von MAS bei ihrer Beschreibung entgegenwirkt. In der Evaluation können Fehler mithilfe des Modells präzise lokalisiert werden.